
November 19, 2025
Hassan Syyid
Background
At Hotglue, we built an embedded ETL product that makes building native integrations for SaaS platforms easier.
When we started, the data engineering ecosystem roughly split into two categories:
Data Movement tools like Fivetran, Stitch, and Airbyte
Data Transformation tools like dbt, compute platforms like Databricks or Spark, or even UI-based products like Alteryx
Generally you need both pieces in order to deliver real value, and often these tools are used together in a ELT / ETL pipeline: extract the data from a source system, transform that data, and load that mapped data into some target system.
Hotglue solved the connectivity and ingestion layer — but we learned that transformation and mapping still consumed most of the time in real projects.
That’s why we built a Python-based transformation layer into Hotglue. Python already had plenty of tooling available to deal with data transformation, so we enabled users to write scripts leveraging libraries like Pandas, Dask, and, more recently, Polars. This made Hotglue far more versatile and able to handle the end-to-end data integration process.
However, writing mapping scripts still required significant engineering time — especially for people who weren’t Python experts. That development process quickly became the most time-consuming part of configuring integrations in Hotglue.
The rise of GenAI coding
As LLMs gained popularity, we saw how good they became at writing Python code, especially when it came to simple data transformation work.
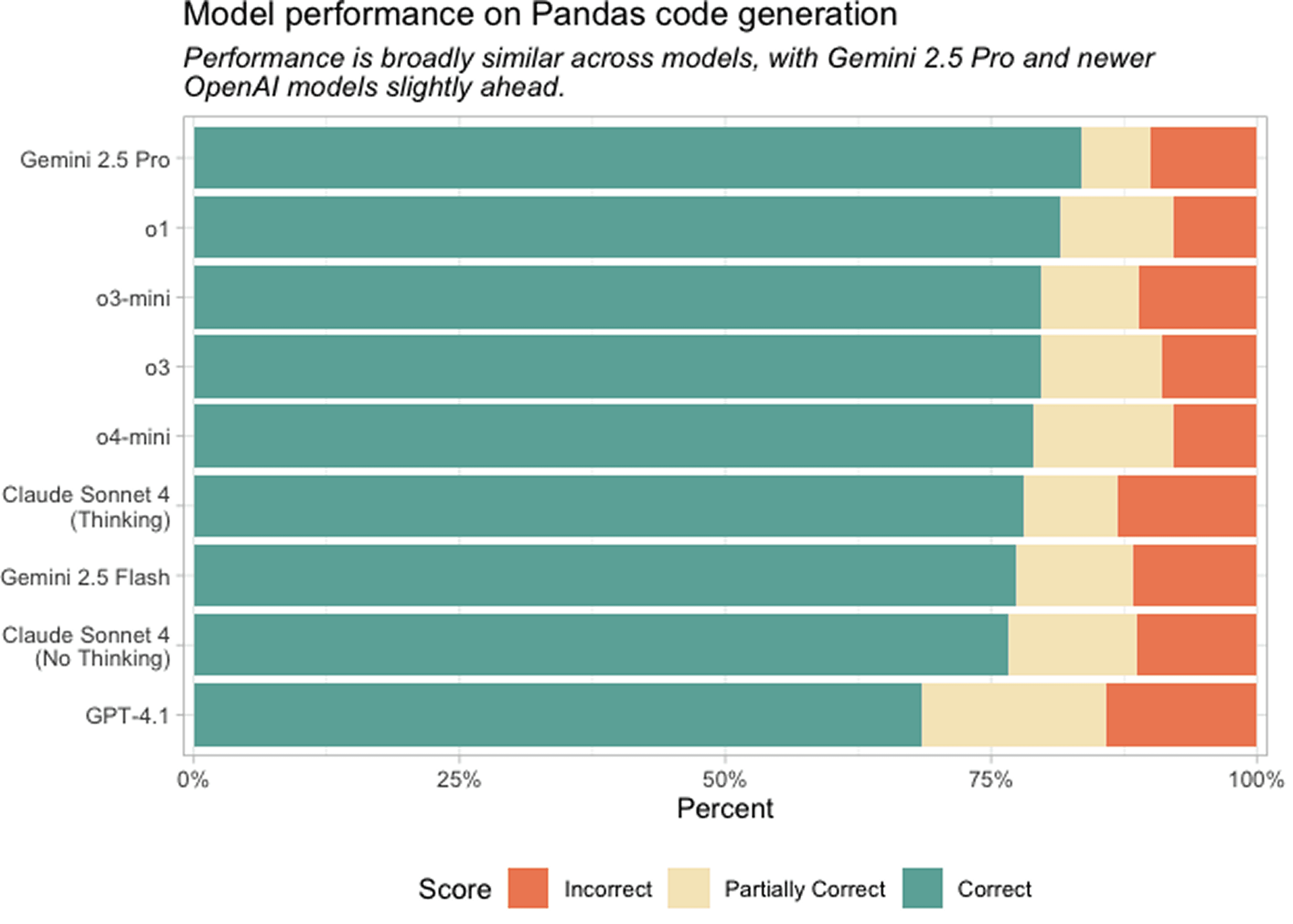
Our team wanted to see if we could use these LLMs to accelerate the process of mapping data in Hotglue – all we needed was to give the LLM context on what we’re trying to do, and let it generate Python code.
LLMs could write the code, but they couldn’t streamline the workflow: exploring data, validating assumptions, testing transformations, and iterating with stakeholders. That’s where most of the time was going.
We realized the real opportunity wasn’t just code generation — it was building a full workflow where exploration, mapping, testing, and deployment all lived in the same place. Almost like Replit or Lovable for data engineers.
The Typical Data Integration Project
Based on the data integration projects we’d seen at Hotglue (usually with ERPs), they generally have the following phases.
Phase 1: Context gathering
Once you do the initial legwork of “getting to” the relevant data – sometimes this can be an involved process of getting access to systems and extracting it – you need to understand it.
For example:
What data am I looking at?
Where is the data I actually care about?
This typically involves some combination of exploring the raw data and talking to a stakeholder who understands the business logic surrounding the data.
There are often weird nuances that come up: “if this column has this text, then you need to ignore this row” or “if the data looks like this, you actually need to join it with this other table”, etc.
Phase 2: Implementation
Once you have all the context you need, you have to codify it somehow. That might look like creating a Python script, it might be an Alteryx workflow, or something else entirely.
Now that it’s codified, you’ll need to verify that the logic is correct – that usually means a human has to sit down and look at the output to verify things line up. This often takes multiple iterations and a good amount of back and forth with stakeholders.
Phase 3: Testing + Deployment
Once you have things fully implemented, there’s typically a QA phase followed by a push to deploy into a production environment.
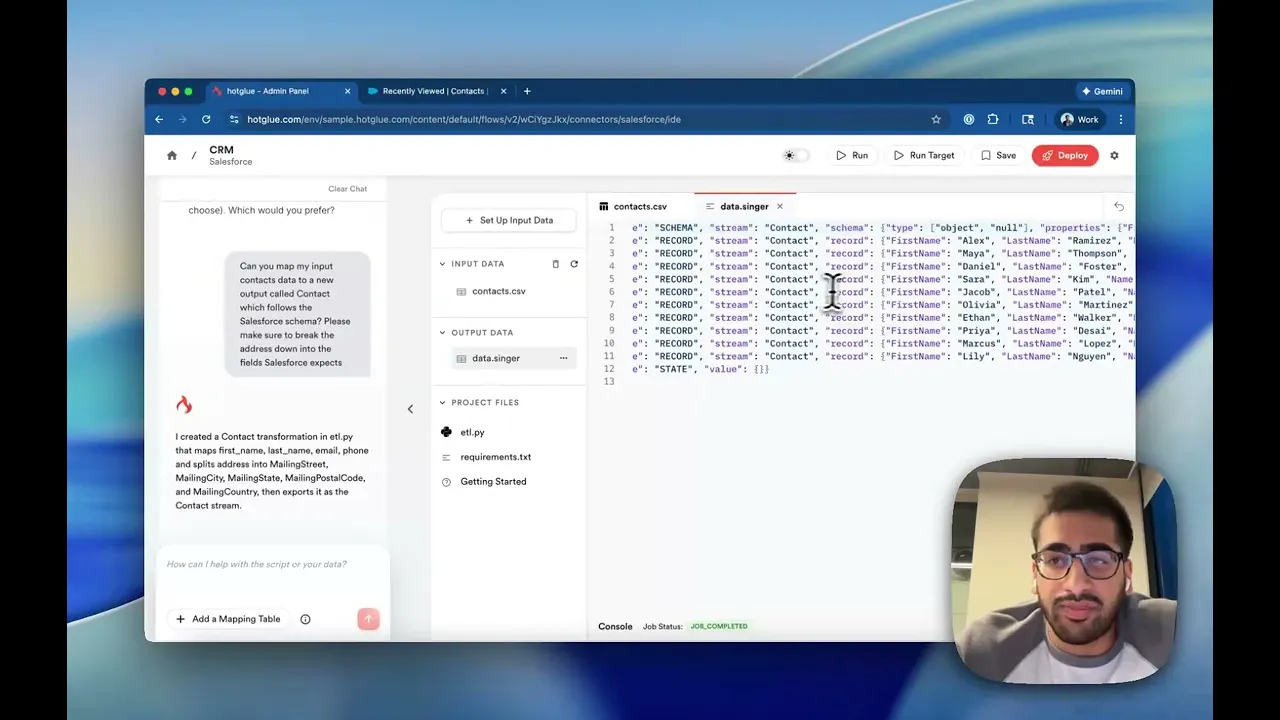
Gluestick
With all this in mind, we created Gluestick, a cloud-based IDE for data engineers with a powerful AI agent to help you through all phases.
Explore data by chatting with it
Rather than manually filtering through data in Excel, you can simply ask questions.
“I’m looking for the pricing data for products, where would that be?”
Gluestick can run queries against the data, figure out where the relevant data is, and show it to you.
Build mappings iteratively in plain English
Since Gluestick has context on the data models, once you identify the data you care about, you can have the agent apply any mappings or transformations you want.
“I want to build an Items table with the columns: id, name, sku, retail_price, and unit_cost. Can you suggest a mapping?”
Gluestick will suggest and apply mappings, and show you sample output data so you can verify and continue iterating. This sort of “human in the loop” workflow enables you to accelerate your work and get to a final result faster.
Easy to test & deploy
The output of Gluestick is a clean, production-ready Python script — meaning you can run it anywhere, or deploy it directly on Hotglue’s data movement infrastructure for scheduled ETL pipelines.
Once a mapping is built, it can often be reused across clients, making each subsequent implementation even faster.
Within Gluestick you can easily test the data pipeline, and even ask questions to understand the behavior
“How come we’re ignoring this row of data?”
“Seems like we’re missing some data, what happened?”
Looking forward
As AI accelerates code generation and businesses demand faster integration timelines, consultants and implementation teams need a way to go from raw data → validated mapping → production pipeline in hours instead of weeks. Our hope is that Gluestick can make that a reality.
Unlike existing tools in the market, Gluestick is a development environment purpose-built for data integration mapping. With features like chat-based exploration of the data, built-in context of business systems like ERPs and CRMs, on top of the ability to write Python transformations, it is a powerful suite of tools for data engineering.
We are still in the early stages of rolling Gluestick out. If you are
a data engineering consultant,
part of a professional services & implementation team,
an ERP/CRM/middleware integration specialist,
or anyone doing repetitive mapping work between business systems
and are interested in trying Gluestick out, we’d love to talk! Join our waitlist.